The above pre-trained skills can now be combined to solve a complex task - the 3 room domain. Here, an agent needs to navigate past obstacles, find an object and collect it, break a wall and then place the object at a specific location (see figure below).

H-DRLN Video
This video showcases the performance of our novel lifelong learning H-DRLN architecture. The H-DRLN incorporates multiple pre-trained Deep Skill Networks (DSNs) and learns to reuse these skills to solve new, complicated tasks in Minecraft. The video is structured as follows:
-
First, we show the performance of the pre-trained skills.
-
The H-DRLN with a single navigation skill solving a two room task in Minecraft.
-
The H-DRLN with a distilled multi-skill network (containing pickup, break, placement and navigation skills) solving a complex 3 room domain in Minecraft.

DSN training
Learning curves of the different skills during training.

3-room domain, performance comparison
Without the use of skills (DQN-DoubleQ) the agent is unable to solve the given task.
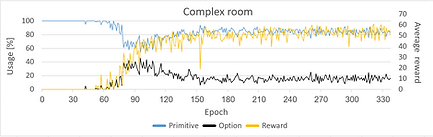
Skill usage over time
Prior to using the skills, the agents performance is bad, after learning to use the skills one can see how the performance increases drastically. Skill usage converges to 20% since the skills aren't perfect and the agent is required to use primitive actions to reach optimal behavior.
H-DRLN Performance
-
The agent learned skills a-priori using a Deep-Q Network (Mnih 2015) training procedure (see DSN learning curves)
-
Using the H-DRLN, the agent managed to solve both the two room and three-room domains (see 3-room domain performance) by learning to re-use the pre-trained skills.
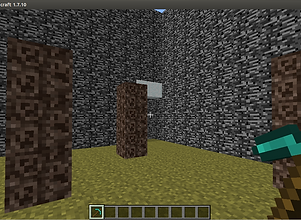
Perspective
The pillars in this domain block the agents line of sight.
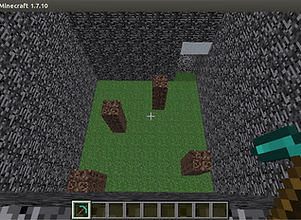
Bird's eye view
The agent is initiated at a random location, looking in a random direction.

Perspective
The block is placed in the center of the room.

Perspective
Second room contains another mission.

Perspective
Success is achieved once the block is placed in the doorway.

Bird's eye view
Identical texture on all walls and floor increases complexity.
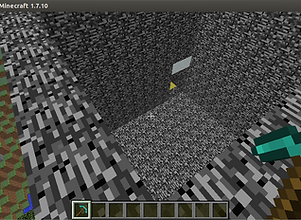
Bird's eye view
Only upon completing this mission the agent receives a non negative reward.
Perspective
Breaking the door, reveals the final room.
Navigation
Pickup
Break
Place
Summary video
Agent performance on the full task.
Video
The agent is required to reach the doorway.
Video
This skills goal is to pickup the colored block.
Video
Selecting the 'break' action while in the doorway leads to success.
Our Deep Reinforcement Learning architecture enables an artificially intelligent Minecraft agent to navigate obstacles, search for an object, pick it up and place it at a pre-defined location. This is the first work to perform a complicated, artificially intelligent task in Minecraft and provides a stepping stone toward lifelong learning.
Learning Reusable Skills
Consider the task of driving a vehicle. This is a complicated task that can be sub-divided into a set of well-defined simple, skills. For example:
(1) Enter the vehicle, (2) turn on ignition, (3) steer the vehicle, (4) transmission control.
Instead of learning to solve the entire task in one shot, which is often extremely complex, an agent can learn each skill separately and then learn how to combine these simple skills to drive the vehicle.
There are many different types of vehicles (cars, buses, trucks etc), yet driving each of them can be broken-down into mastering the four above-mentioned skills. Therefore, once we learn these skills, we can reuse them for driving new, previously unseen vehicles (new tasks). Skill reuse is both powerful and crucial to lifelong learning problems such as Minecraft.
-
Our Deep Reinforcement Learning architecture allows an agent to solve tasks using pre-trained, reusable skills. We refer to these skills as Deep Skill Networks (DSNs)
-
Each skill is trained in a separate domain a-priori.
-
An agent then learns how to combine and reuse these skills to solve a given task by utilizing our Hierarchical Deep Reinforcement Learning Network (H-DRLN) architecture.
-
The agent receives negative rewards at each time-step until it completes the task, at which point it receives a non-negative reward.

A Deep Hierarchical Approach to Lifelong Learning in Minecraft
Minecraft is a creative, first player 'open-world' game with over 100 million online users. In this game, a player is free to roam, hunt for food, build structures, fight monsters - the options are endless. As a result, Minecraft is a non-trivial, unsolved AI problem and an exciting research platform for lifelong learning.
Authors
Chen Tessler

Shahar Givony


Tom Zahavy

Daniel Mankowitz

Shie Mannor
Using the H-DRLN in Minecraft
We wish for an artificially intelligent Reinforcement Learning agent to solve complicated tasks in Minecraft by using our H-DRLN architecture. First, we have to train the skills a-priori. We focus on four skills:
(1) Navigation - An agent navigates from point A to point B
(2) Pickup - An agent learns to approach and pickup an object
(3) Break - Navigate to, and destroy an object
(4) Place - Take an object to a pre-defined location

Our novel H-DRLN Architecture
This is our exciting, new architecture that enables an agent to solve complicated tasks using pre-trained, reusable skills. As seen in the above diagram, the H-DRLN architecture has outputs that correspond to primitive actions (a1, a2, ..., am) and different skills (DSN1, DSN2, ..., DSNn). The Deep Skill Module (bottom) represents a set of skills. It receives an input and a skill index and outputs an action according to the corresponding skill policy. The architecture of the deep skill module can be either a DSN (skill) array (A) or a Distilled Multi-Skill Network (B).
Discussion
-
We have provided the first results for learning Deep Skill Networks (DSNs) in Minecraft, a lifelong learning domain.
-
Our Minecraft agent learns how to reuse skills on new tasks by utilizing our Hierarchical Deep RL Network (H-DRLN) architecture.
-
We incorporate multiple skills into the H-DRLN using (1) the skill array and (2) the scalable distilled multi-skill network, our novel variation of policy distillation.
-
We show that the H-DRLN provides superior learning performance and faster convergence compared to the DDQN, by making use of temporally extended actions.
-
We see this work as a building block towards truly general lifelong learning using hierarchical RL and Deep Networks.
Life-long Learning
Lifelong learning considers systems that continually learn new tasks, from one or more domains, over the course of a lifetime. Lifelong learning is a large, open problem and is of great importance to the development of general purpose Artificially Intelligent (AI) agents.
Definition: "Lifelong Learning is the continued learning of tasks, from one or more domains, over the course of a lifetime, by a lifelong learning system. A lifelong learning system efficiently and effectively (1) retains the knowledge it has learned; (2) selectively transfers knowledge to learn new tasks; and (3) ensures the effective and efficient interaction between (1) and (2)" (Silver, Yang, and Li 2013).

How did we achieve this?
-
- We incorporate knowledge retention using 'multi-skill distillation'.
-
- Selectively transfer knowledge using 'reusable skills'.
Distilled Multi-Skill Network
The "Distilled Multi-Skill Network" is our novel variation of policy distillation.
In our method, we compress all the skills into a single network using policy distillation and demonstrate that our method can scale with the number of skills.
In a life-long learning setting, the amount of skills accumulated over time is unbounded. Using our distillation technique, we are able to reduce resource usage drastically while maintaining adequate single skill performance.

Why skills?
In reinforcement learning, the complexity of the problem grows exponentially in the number of state and action variables. Temporally extended actions (skills) allow the agent to solve and plan at a "higher-level", hence reducing the complexity of the original problem.