Reward Constrained Policy Optimization
- Chen Tessler

- Aug 1, 2019
- 2 min read
Joint work with Daniel J. Mankowitz and Shie Mannor.
Published at the Seventh International Conference on Learning Representations (ICLR) 2019.
What?
In this work we propose the Reward Constrained Policy Optimization (RCPO) learning paradigm, a three-timescale approach to learning complex constraint satisfying policies.
Why?
As reinforcement learning systems transition from simulation-based environments into practical real-world domains, they are required to not only optimize a given reward signal, but also ensure certain behaviors - such as abiding the laws. For instance, while an autonomous vehicle is tasked at arriving as fast as possible to the destination, it is required to not only provide a comfortable ride to the passengers, but also abide by the rules (such as speed limits) and ensure the safety of others.
While previous works [1,2] have tackled immediate constrains (single-step-hard constraints such as not entering a region) or discounted constraints (in which the discounted sum, similar to the value, of costs is constrained to reside below a threshold), in this work we provide a framework for tackling more complex constraints, which under reasonable assumptions, finds a feasible solution.
How?
We propose a 3-timescale approach, detailed below.

Similar to an actor-critic scheme, the critic moves on a faster timescale than the actor, such that it holds an updated estimate of the policies value. In this work, the third timescale (the slowest) controls the reward signal or more specifically, the weight applied to the cost. As we consider general constraints, and not only discounted[2]/immediate[1] constraints, the ability of the agent to satisfy the constraints must be evaluated by sampling entire trajectories (line 10) and testing for constraint satisfaction.
In simple terms, as long as the agent violates the constraints, the weight increases until the cost dominates the reward. Under mild assumptions, which we provide in the paper, this approach will converge to a constraint satisfying solution.
Experiments
We perform an experiment in the MuJoCo control suite (an additional tabular domain is presented and analyzed in the paper). In this task, the require the agent to maximize the reward, while retaining the average torque usage (power consumption) below a certain threshold.

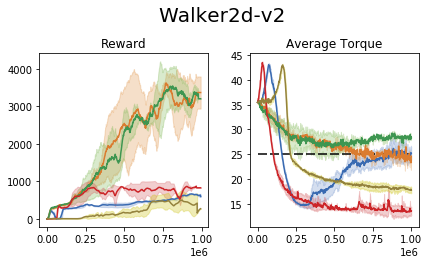

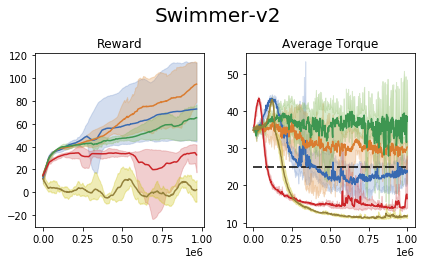

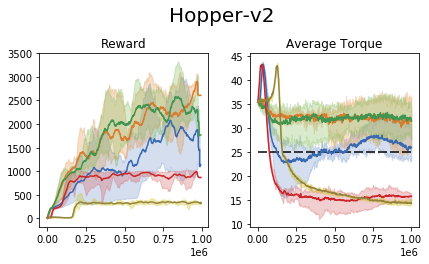

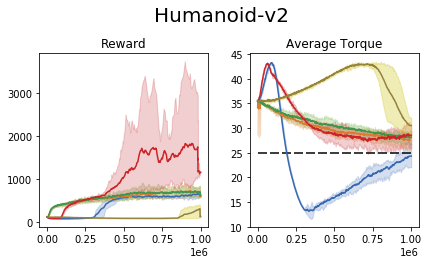

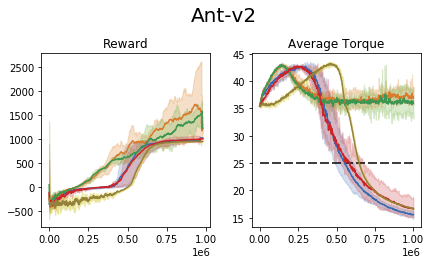

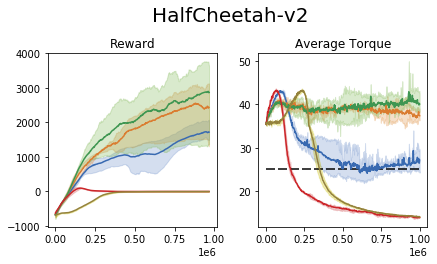


We compare our approach to the common 'reward shaping', in which the algorithm designer manually crafts a reward signal in an attempt to obtain certain behavioral traits. These results show that (1) the task of reward shaping is hard, (2) successful costs do not easily transfer across domains, (3) RCPO is capable of finding constraint satisfying solutions.
Conclusions
In this work we presented an approach for learning constraint satisfying policies, even when accounting for complex non-standard limitations (such as probabilistic and average constraints). We validated our approach on two domains showing.
Bibliography
[1] Gal Dalal, Krishnamurthy Dvijotham, Matej Vecerik, Todd Hester, Cosmin Paduraru, and Yuval Tassa. Safe exploration in continuous action spaces. arXiv preprint arXiv:1801.08757, 2018.
[2] Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. arXiv preprint arXiv:1705.10528, 2017.



Comments